
So, you want your systems to be dependable in 2026 and beyond? That’s obvious! But do you know that you need more than a handful of monitoring dashboards and heroic on-call engineers? Yes, you need a plan—a measurable SRE strategy and roadmap that ties technical work to your business outcomes.
Below, we’ll walk through a detailed SRE strategy and roadmap with tactics you can apply immediately. Also, we’ll help you understand why it makes sense to consider reliability engineering consulting or cloud reliability consulting when your internal bandwidth falls short.
What is Site Reliability Engineering (SRE)?
Initially introduced by Google in 2003, SRE is a discipline that incorporates different aspects of software engineering into infrastructure and operations. It is essential for modern organizations to aim for high reliability and performance.
Since the premise of both is the same, SRE can be compared with DevOps. However, DevOps focuses more on the delivery, whereas SRE is all about building system reliability. The aim of SRE is to solve issues related to reliability by:
- Continuously monitoring the system
- Setting up system alerts
- Establishing standards (error budgets)
- Automating repetitive tasks like toil automation
- Adhering to SLA, SLO, and SLI metrics
Claim Your FREE SRE Quote Today!
| Category | Details |
|---|---|
| Quick Summary | Ensure systems are reliable, fast, & scalable. |
| Goal | Ensure systems are reliable, fast, & scalable. |
| Key Focus | Uptime, performance, AI automation, incident response. |
| Core Metrics (SLIs) | Latency, availability, error rate, & saturation. |
| Service Targets (SLOs) | e.g., 99.9% uptime, <1% errors. |
| Error Budget | Allowed downtime before slowing new releases. |
| Incident Response | Alerts, escalation, RCA, post-mortems. |
| Automation | Auto-scaling, CI/CD, self-healing, IaC. |
| Tools | Prometheus, Grafana, Kubernetes, Terraform. |
| Deployment Practices | Canary, blue–green, rolling releases. |
| Outcomes | Lower downtime, quicker recovery, faster releases. |
How to Implement SRE? A Step-by-Step Guide
The SRE roadmap is built from foundational knowledge of systems and AI automation, through specialized cloud to reliability practices. Here are some major steps you need to follow in order to ensure strong SRE implementation in 2026.
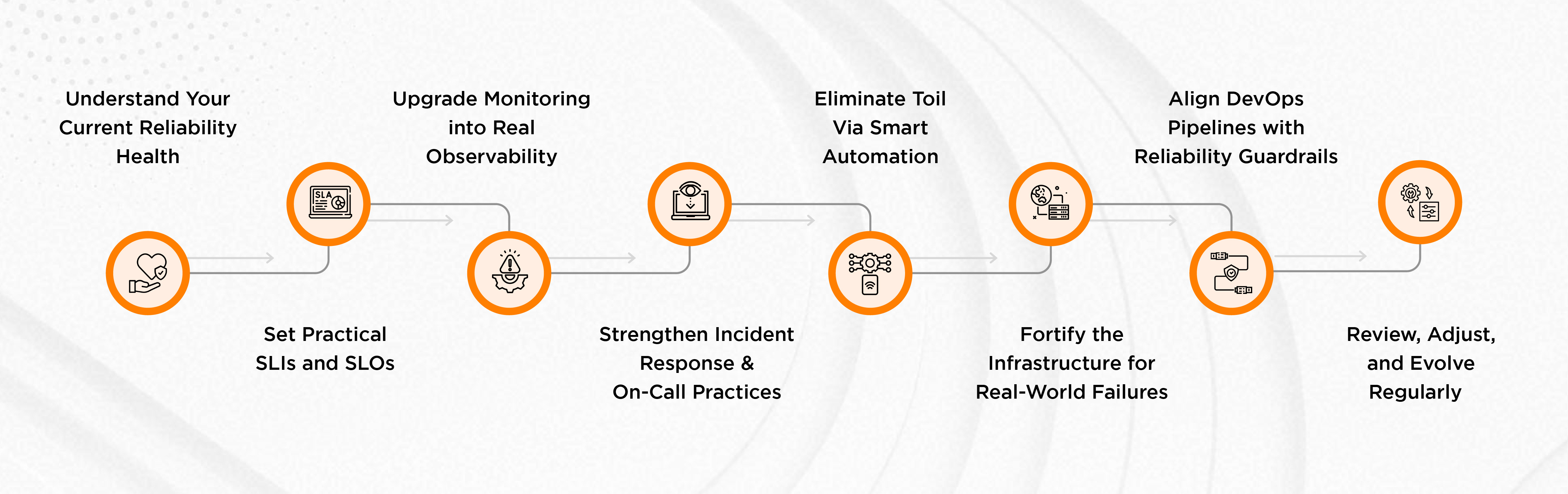
Step 1: Understand Your Current Reliability Health
Before you fix anything, you need a clear picture of how your systems behave today. That means checking uptime trends, on-call load, alert noise, recurring failures, and how quickly teams respond to incidents. Think of it as a full “fitness test” for your platform.
Step 2: Set Practical SLIs and SLOs
Instead of selecting arbitrary targets, define reliability objectives that mirror real customer expectations. SLIs (what you measure) and SLOs (your promised thresholds) are your north star. These guardrails guide teams in balancing speed and stability sans guesswork.
Step 3: Upgrade Monitoring into Real Observability
Collecting logs isn’t enough. This step is all about enhancing visibility regarding the behavior of your systems, the dependencies among constituent components, and what signals actually foreshadow trouble. This is about detecting issues before the users can notice.
Step 4: Strengthen Incident Response & On-Call Practices
Teams must react to outages quickly and calmly. This includes creating clear playbooks, assigning well-defined escalation paths, practicing chaos drills, and running blameless post-incident reviews. The aim is to make your response predictable—even during high-stress situations.
Step 5: Eliminate Toil Via Smart Automation
Determine repetitive manual work, which slows teams down, such as deployments, common fixes, configuration chores, and routine checks. The results? You can ensure faster operations and happier engineers with more time to focus on meaningful tasks.
Step 6: Fortify the Infrastructure for Real-World Failures
In this phase, you build systems that degrade gracefully rather than collapse. It could be implemented by multi-zone redundancy, rate limiting, circuit breaking, load balancing, and resilience testing. Or, in short, you prepare the system for “when things go wrong,” not “if they go wrong.”
Step 7: Align DevOps Pipelines with Reliability Guardrails
Speed and stability should not be in conflict. Introduce quality gates into CI/CD, add progressive rollouts, make sure that automated tests cover critical flows, and embed resilience checks into deployment pipelines. Thus, teams can ship fast but not break production.
Step 8: Review, Adjust, and Evolve Regularly
A roadmap isn’t chiseled in stone. Revisit your reliability targets every quarter, review incident trends, adjust SLOs, refine processes, and fix blind spots. As the products change, the reliability strategy will have to change along with them.
The Only SRE Strategy and Roadmap You Need in 2026
An effective SRE strategy and roadmap serve as the blueprints on how the enterprise will architect, deploy, and sustain reliable systems. The following roadmap defines the objectives of reliability, integrates AI-driven automation, strengthens observability, and builds a continuously improved culture:
-
Leverage Reliability Engineering Consulting
Very few organizations possess in-house SRE expertise. Therefore, accelerating your SRE journey is better availed by using reliability engineering consulting services. The value of this guidance is immense in shaping infrastructure reliability and mitigating risk while optimizing performance and cost efficiencies.
Expert SRE consultants will help you with keen insights into:
- Best SRE practices
- Technology selection
- Tailored process frameworks fitting your environment
-
Integrate DevOps and SRE Consulting for Holistic Operations
Combine DevOps and SRE into a forceful partnership that fills the gap between development velocity and operational stability. This would mean enabling organizations to integrate reliability upfront in the software development lifecycle and create rigorous production reliability management by harmonizing the disciplines.
The results of such synergy are:
- Accelerated deployment pipelines
- Proactive incident responses
- Fine-tuned change management to form the backbone of reliable operations
-
Create Your Reliability Management System
Production reliability management is at the core of SRE success: an active process of continuous monitoring, analysis, and optimization of system health across production environments. It’s necessary to install sophisticated observability tools, deploy SLIs and SLOs, and automate workflows for remediation to build this framework.
With this kind of capability, you are able to surface anomalies a lot faster and drive down MTTR. That bolsters user confidence and continuity.
-
Embrace Reliability Operations for Continuous Advancement
Reliability operations span beyond one-time implementation to embedding resilience as a continuous organizational competency. Here, infrastructure reliability services ensure infrastructure development that keeps up with digital transformation trends.
Here, professional AI SRE consulting supports in-house teams to:
- Fine-tune their processes
- Identify risks and gaps
- Implement adaptive strategies aligned with emerging threats
-
Implement SRE Solutions
After all, the implementation of SRE needs orchestration around technology, processes, and people. This is exactly where the SRE implementation services step in, with hands-on assistance. This makes sense when you want to accelerate the assimilation of IT reliability solutions across your enterprise ecosystem.
Professional SRE implementation solutions will help you take care of:
- Piloting initiatives
- Scaling mature programs inclusive of automation frameworks
- Training and cultural change management
-
Achieve Sustainable Excellence Through SRE
Holistic reliability engineering solutions transform reactive IT management into proactive business enablers in their pursuit of agility and customer satisfaction. Embedded resilience at each operational layer minimizes downtime, optimizes resource utilization, and fosters innovation without sacrificing dependability.
In Conclusion
With the digital landscape continuing to move into uncharted levels of complexity, the need for a clearly articulated SRE strategy and roadmap cannot be more emphasized. Here, collaboration with experienced professionals providing AI SRE consulting, cloud reliability consulting, and end-to-end SRE advisory services will prepare your organization for systems that can face adversity and transformational growth.
Ready to make your systems robust against uncertainty? Connect with SecureSmartz to adapt state-of-the-art DevOps and AI reliability engineering designed for modern dynamic challenges.
Frequently Asked Questions
- SLIs are the data
- SLOs are the internal goals for that data
- SLAs are the external promises derived from those goals
- Gaps in reliability
- Slow incident response
- Misaligned DevOps goals